Spring Data Redis Performance issues with Redis Clustered
MultiGet or MGET
Issues started with multiGet or MGET
redisTemplate.opsForValue().multiGet(keys)
I ran command above in Clustered Redis and I saw that there were several MGET commands executed in different threads. I expected there would be one MGET command.
Later, I learned that my keys were landing to different slots. That’s why Spring Data Redis was executing several commands for each key.
There was nothing to do with it.
Pipelining
Second part of my work was I had several entities and for each entity I had to run several GETBITs. So I thought I can use pipelining.
Pipelining is recommended when you want to improve performance of your Redis operations. Because operations did not require to be serial, pipeline seemed perfect solution. In pipeline, commands were sent in batch through Redis connection and we just have to wait for answers.
Unexpected performance with pipelining
So I ran pipelining and was shocked to see following
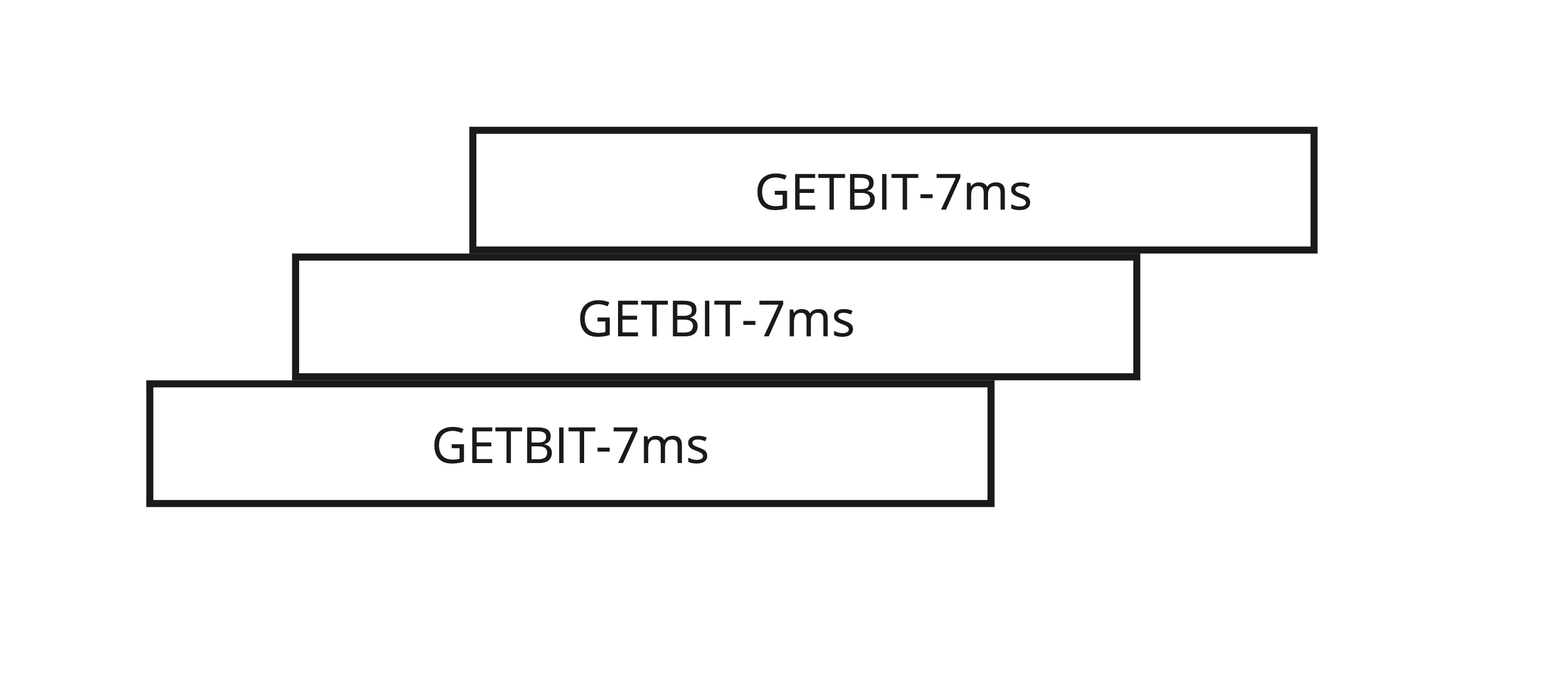
These were huge numbers.
Suspecting that it was related with pipelining, I tried to ran GETBITs in plain for loop and saw that something was happening with pipeline.

Of course, I could have executed those GETBITs parallely using threads but I wanted to squeeze better numbers so I decided to try LUA script.
The thing you should remember that all keys that are used in LUA script should have to be in same slot.
local bit1 = redis.call("GETBIT", key, value1)
local bit2 = redis.call("GETBIT", key, value2)
local bit3 = redis.call("GETBIT", key, value3)
And I saw following, which was huge improvement.

EVALSHA - Evaluate a script from the server’s cache by its SHA1 digest.